语音识别学习总结
前端时间用HTK磕磕碰碰的走了一遍语言识别的整个流程,对语言识别有了个初步的了解,下面是自己对这段时间学习的总结。
语音识别系统整体上包括两大部分:训练和识别。 训练:海量语音、语言数据库 —(信号处理和知识挖掘)—> 声学模型+语言模型 识别:利用训练好的“声学模型”和“语言模型”对用户说话的特征向量进行统计模式识别(又称“解码”),得到其包含的文字信息, 乔正“声学模型”和“语言模型”。 一个最基本的语音识别系统(去除了训练部分的识别系统)如下图所示
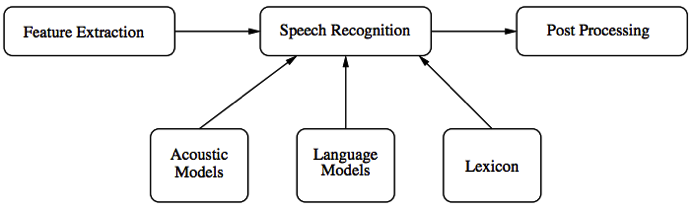
主要包括一下四个模块 1.特征提取 a)用HCopy可以对语音材料库中的声音文件提取MFCC声纹特征 2.声学模型 a)用HInit,Hcompv,HRest等工具来训练声学模型(HMM) 3.语音模型 a)用HParse来训练语音模型 4.字典 a)发音对应到文字 有了以上准备之后就可以用HVite进行识别: 识别的大概原理就是,用生成的语音模型形成图(用字典把语音模型的词转成与其对应的基本元),图的点就是词的基本元,图里边的权值根据声学模型的HMM计算出来,然后对提取出来的MFCC声纹特征(理解成一个矩阵数组)在图里找路径正好覆盖它。这条路径对应的词就是识别的结果 最后HTK给我的感觉就是HTK的参数设置有点乱,最后整个试验过程中在语料准备方面微微遇到点麻烦。
参考链接: HTK官方主页:http://htk.eng.cam.ac.uk/ 新加坡国立大学语言识别课件:http://www.comp.nus.edu.sg/~simkc/slides/ 语音识别工具箱之HTK安装与使用: http://www.cnblogs.com/mingzhao810/archive/2012/08/03/2617674.html
blog comments powered by Disqus